
技术及其原理/Technology and its principles
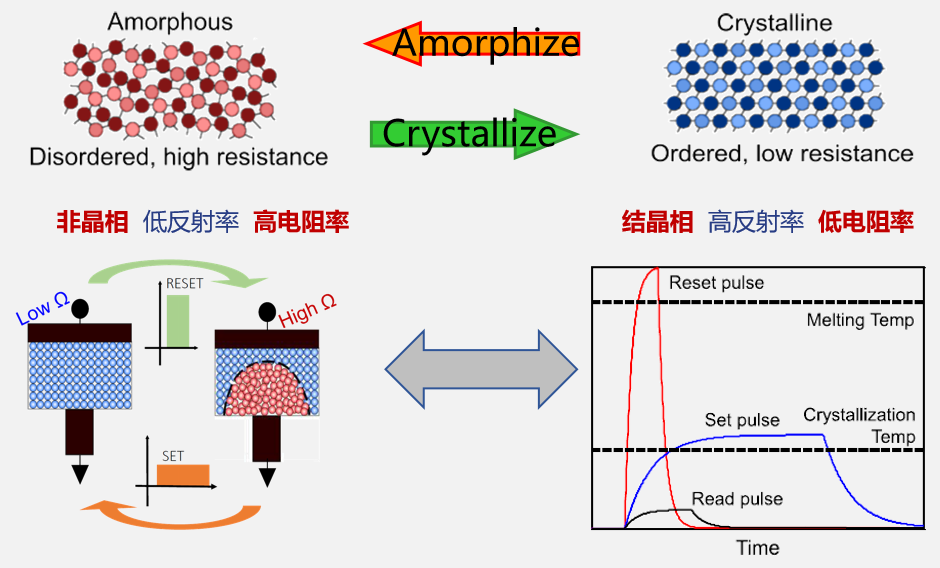
相变存储不同于需要依靠电子/电容来存储信息的第三代存储,它是依靠物理材料在非晶态(Amorphous)及晶态(Crystalline)间的转变,造成高低电阻的区别来存储0和1的信息。
透过电流对金属硫化物的加热和降温使其在晶态和非晶态间转变而完成“写”,“擦”,“读”的过程。因为物理的相变在不加热的时候是稳定的,不加热,PCM物质的相就不会改变,所以信息就不会丢失,从而达到非易失性的性能。并且PCM不依靠电子/电容来存储信息,就不会像第三代存储(DRAM及3D NAND),其信息会因为辐射的影响而改变。目前无论是INTEL、IBM、三星、海力士,还是意法半导体、长存、AMT都已经验证了存储单元的稳定性,从而可以广泛应用。
●“写” 过程
通过短暂的强电压脉冲转变的热能使相变材料达到熔点之后再快速淬火,使晶相(有序)遭到破坏,由多晶相进入非晶相。
●“擦”过程
通过一个时间较长、强度中等的电压脉冲转换的热能使相变材料的温度升高到结晶温度以上、熔化温度以下,并维持一定时间,使相变材料转化为多晶相。
●“读”过程
在不激发相变的条件下通过测量相变材料的电阻值来实现数据的读取。

特性及优势/and Benefits
PCM技术基于材料的相变存储0和1的信息,因此相较于电子/电容存储具有以下特点和优势:
1、非易失性:即断电后依然保持数据,而同类的DRAM则需要每十五分之一秒耗电刷新一次。
2、兼容性:PCM技术的工艺完全与CMOS兼容,在当前成熟工艺条件下即可完成,不仅可用于独立式产品,也可以开发嵌入式产品。
3、低成本:PCM在成熟工艺条件下,可以使用更少的光罩,从而降低成本,亦可极大地降低用户购买成本和运营成本。
4、微缩性:PCM的存储单元目前已经证明可以微缩到5nm。因此可以作成极小的低功耗存储单元。
5、抗辐射:PCM技术不使用电子/电容存储信息,不受辐射的影响,在未来航空航天应用中具有无可比拟的优势。
6、高低电阻差特性:100倍以上的阻值差,使得PCM技术可以从容地开发从低容量到高容量的存储产品,几乎可以覆盖当前市场上的所有存储产品。
7、类人脑神经网络特性:PCM可以模拟人脑发射信号,经过思考并对信号做出反应(STDP/尖峰时序连贯可塑性),已经人工智能通用芯片发展的重要方向。

知识产权/Intellectual Property
北京时代全芯存储技术股份有限公司(简称AMT)是继Intel之后国内第一家量产相变存储器的企业。AMT深耕新一代相变技术十余年,知识产权来源清晰,过程合法,目前拥有PCM相关专利四百多项,另还有五十九项审核中,以及 一万多项专有技术(Know-How)。AMT已经形成完全自主可控的知识产权布局,是一家国际化的民族企业。
AMT总部位于北京市海淀区蓟门壹号,有近100名海内外员工、包括多名博士、硕士等尖端半导体人才组成的国际化团队,是国内现在唯一一家完成PCM工艺、材料、设计及产品验证的半导体公司。AMT于2019年1月25日进行股份制改造,当前注册资金11.62亿。
AMT是中关村高新技术企业,并得到北京经信局和财政局的高精尖产业发展资金的支持。研发项目被北京科委及中关村管委会选定为“颠覆性技术和研发成果转化项目”及中关村国家自主创新示范区提升国际化发展水平项目。
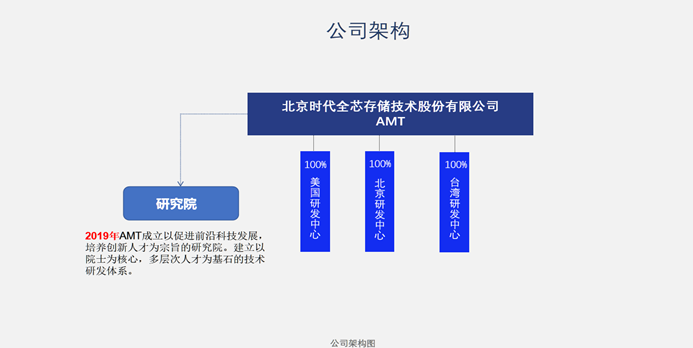
全球研发中心/Global R&D Center
AMT总部设在北京海淀区,有北京,台湾,及美国的三个全资研发中心,并设有前沿科技发展的研究院,建立以院士为核心,多层次人才为基石的技术研发体系,并与代工基地合作。

存内计算(PIM)/In Memory Computing (PIM)
充分利用PCM非易失性,可以将所有的数据参数存储在PCM内,而不会像以GPU/CPU为核心的人工智能和数据中心,必须将数据参数在GPU/CPU和存储之间来回地传输,因此以PCM技术为核心的算力加速产品将具有更低的延迟和功耗,并且可以在存内实时更新运算参数,透过存内参数的不断学习和训练更新来实现运算的加速。其中低功耗高运算速度的模拟电路可以在一个脉冲时段(Single Clock Cycle)内完成整个矩阵的运算,相对于GPU/CPU的逐行逐列的乘法与加法运算(Multiplication and Addition/MAC),运算效率可大幅度地提升。PCM的制程工艺与CMOS完全兼容,因此低成本且成熟的数字电路基本上可以无限使用,可以用Digital-Assist及Auto-Calibration来简化DAC和ADC的设计。所以在推断(Inference)工作负载下,PIM-PCM加速器在使用40/28nm成熟工艺下即可达到5nm工艺制造的GPU同等的性能。
以PCM技术为核心的算力绿色PIM加速器,可以提供绿色节能并算力加速的AI解决方案,同时满足边缘计算和大算力的需求。IBM于2023年8月23日在Nature发布以相变技术为核心的低能耗算力加速芯片。其算力是最先进GPU芯片的14倍。
成果:
● 非冯·诺伊曼架构消除数据和参数在GPU/CPU和存储之间的传输所造成的延迟和功耗
● 运算的加速
● 同时适用于大算力和边缘计算应用

首页
pcm技术
PCM解决方案
产品中心
关于我们
电话:010-62486432
地址:北京市海淀区西土城路蓟门壹号 6号楼405-2
—————————————————————————————————
版权所有©北京时代全芯存储技术股份有限公司
京ICP备2021024950号-1
京公网安备 11010802035888号